Workflows
Analyzing data involves a sequence of tasks, including gathering, cleaning, and processing data. These sequence of tasks are called a workflow or a pipeline.
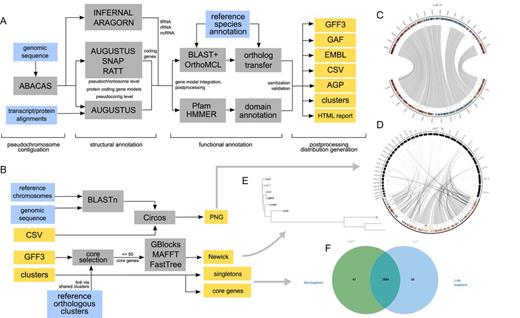
Steinbiss, S., et al., (2016). Companion: a web server for annotation and analysis of parasite genomes. Nucleic acids research, 44(W1), W29–W34. https://doi.org/10.1093/nar/gkw292
Workflow management systems
WfMS contain multiple features that simplify the development, monitoring, execution and sharing of pipelines. Key features include;
- Run time management: Management of program execution on the operating system and splitting tasks and data to run at the same time in a process called parallelization.
- Software management: Use of technology like containers, such as Docker or Singularity, that packages up code and all its dependencies, so the application runs reliably from one computing environment to another.
- Portability & Interoperability: Workflows written on one system can be run on another computing infrastructure e.g., local computer, compute cluster, or cloud infrastructure.
- Reproducibility: The use of software management systems and a pipeline specification means that the workflow will produce the same results when re-run, including on different computing platforms.
- Reentrancy: Continuous checkpoints allow workflows to resume from the last successfully executed steps.

Language
-
Nextflow scripts are written using a language intended to simplify the writing of workflows. Languages written for a specific field are called Domain Specific Languages (DSL), e.g., SQL is used to work with databases, and AWK is designed for text processing.
-
In practical terms the Nextflow scripting language is an extension of the Groovy programming language, which in turn is a super-set of the Java programming language. Groovy simplifies the writing of code and is more approachable than Java. Groovy semantics (syntax, control structures, etc) are documented here.
-
The approach of having a simple DSL built on top of a more powerful general purpose programming language makes Nextflow very flexible. The Nextflow syntax can handle most workflow use cases with ease, and then Groovy can be used to handle corner cases which may be difficult to implement using the DSL.
DSL2 syntax
Nextflow (version > 20.07.1) provides a revised syntax to the original DSL, known as DSL2. The DSL2 syntax introduces several improvements such as modularity (separating components to provide flexibility and enable reuse), and improved data flow manipulation. This further simplifies the writing of complex data analysis pipelines, and enhances workflow readability, and reusability.
This feature is enabled by the following directive at the beginning a workflow script:
nextflow.enable.dsl=2